
大家好,今天是2024年2月10日,这是我们在大年初一的第二期日报。因为昨天是大年三十,市场也比较平稳(稳定上涨),没有什么大新闻,所以我跳过了更新。今天在这里就发一期闲聊,延续一下写完上一期日报后亟待抒发的感想和心情。
承蒙大家错爱,上一期关于AI和GPU业内调研的日报获得了很多关注,也有很多人因此加入了我们的会员。诚惶诚恐,只希望我们的内容未来能对大家有更多帮助。也欢迎会员朋友们在群里多多讨论,充分利用自己的权益,充分利用大家一起交流的氛围。
今天的第二期日报,就来谈一谈我对AI市场最近表现的一些个人看法:AI的狂热对整个行业,到底意味着什么?
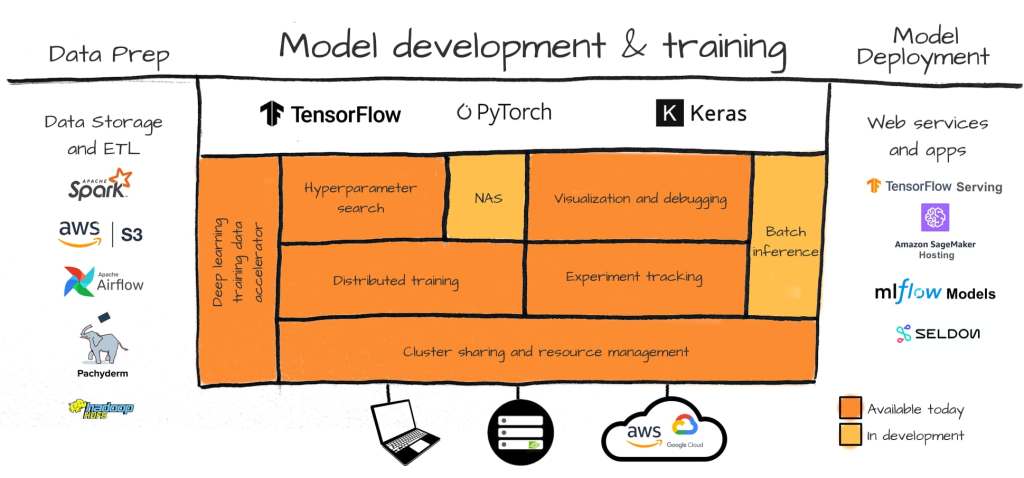
我认为,不论AI最后落地成功与否,它都已经永久性的改变了我们所熟知的行业,数据中心的基础架构:Infrastructure
这一波浪潮的兴起,最大的受益者其实并不是大家理所当然认为的深度学习科学家,或Data Scientists,而是Infra工程师
之所以会出现这样的局面,其原因首先在于LLM的模型本身结构其实比较简单,属于某种编码模块(Transformer)的多次重复。一个70B大小的模型,和7B大小模型的最大差别,其实是这种模块重复的数量,和里面embedding和attention layer矩阵宽度的大小,而不是模块类型。虽然说最新最强的模型用Mixture of Experts(一种稀疏连接的矩阵)取代了Dense Layer(密集连接层)。
这就导致,留给模型科学家们发挥的空间,其实并没有大家想像的那么大。
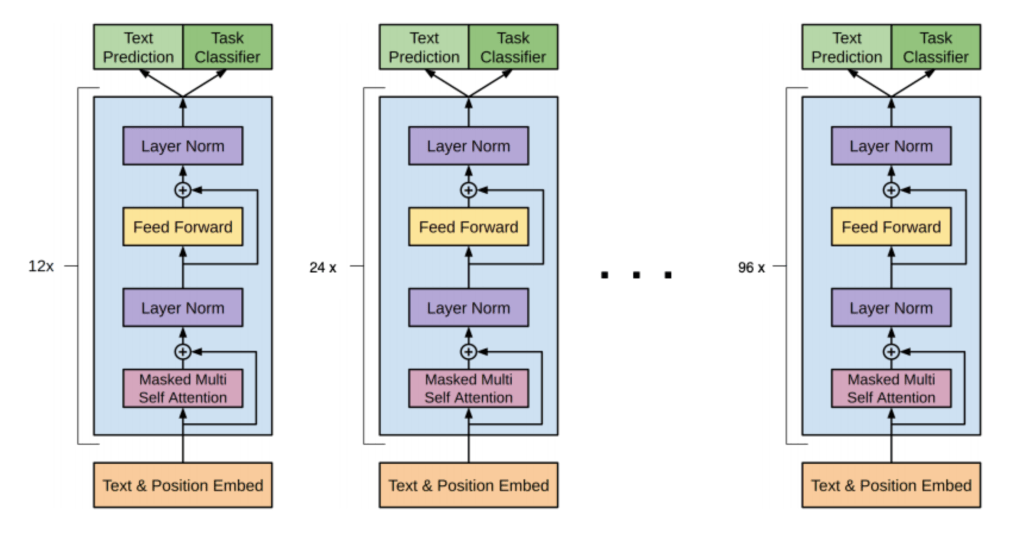
而大模型训练本身则带来了诸多新的特性,给硬件提出了全新的要求:
- 如庞大的模型参数需要的大显存,
- 海量的训练数据带来的超长训练时间,以一个70B大小的模型为例,现在需要训练大概一百万小时(按单个H100GPU计算)
- 实际上需要2000个GPU才能将训练时间限制在合理区间
- 几千张显卡多卡训练带来的卡间通信瓶颈问题
- 等等
辅以各大厂商对LLM预训练爆炸性的需求,在传统数据中心磨练多年的Infra程序员们迎来了职业第二春,开启了他们全新的职业之路。
大模型的训练有两大特点:一个是模型越大、推理能力越强,这也叫Scaling Law。因为大家现在还在推进LLM AI的极限,尝试冲击AGI,所以70B,乃至170B以上的参数依然是现阶段训练的重点。
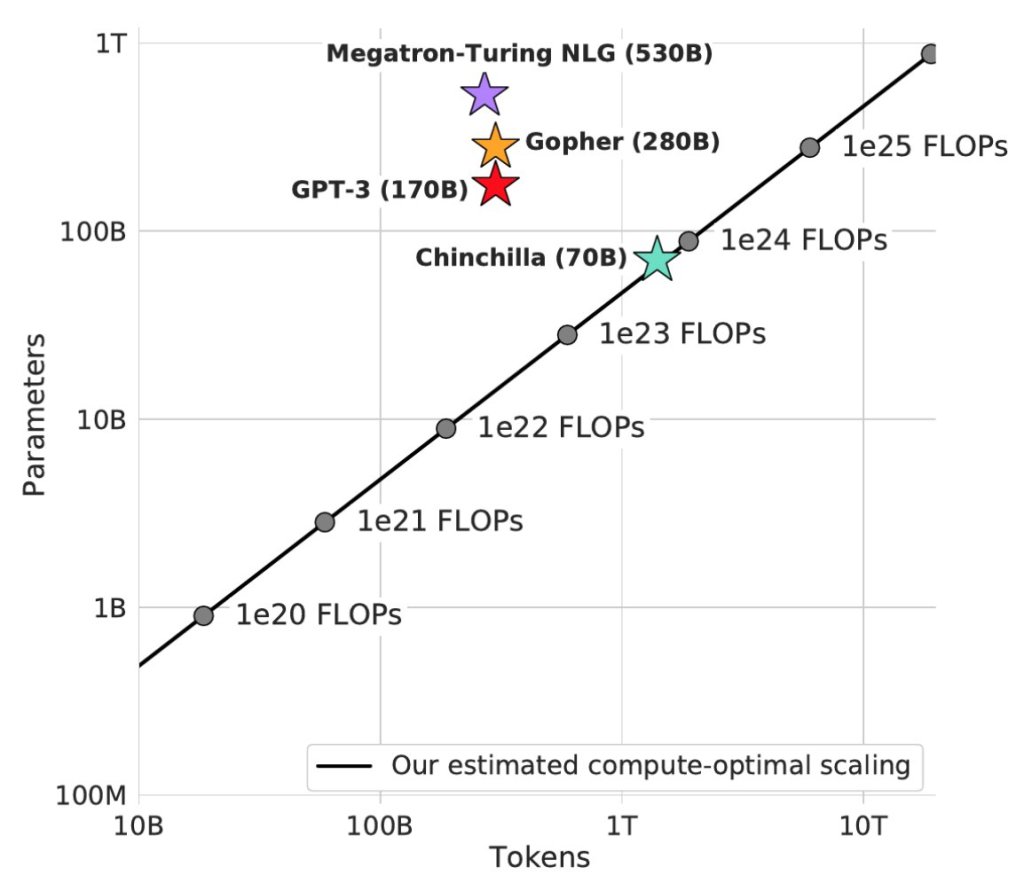
而这种大模型对显存的需求是多少呢?


《“周末闲聊:这一波AI狂潮如果过热的话,对业内到底意味着什么?”》 有 2 条评论