

大家好,今天是2024年3月23日星期六。如昨天日报所说,这是一期特别篇。我们将和大家一起来了解一下,本次英伟达在2024GTC发布的全新Blackwell AI芯片,到底牛在哪里,又有什么无法逾越的护城河呢?
Sponsor:如果您是大陆居民并且对美股投资感兴趣,但尚不清楚如何开户,不妨阅读本文,参考我们的长桥App开户图文全记录。他们现在有一个活动:月底之前开户可以获得终生免佣和价值数百元的股票券。其中通过本站链接开户的,能再额外获得100元股票券。
算力的五个层次
在具体分析Blackwell之前,我们可以先从黄仁勋的分析师电话会议中,对GB200的设计理念做一个大致的了解。
GB200是英伟达推出的最强大的AI超级芯片,他们也可能组成这个地球上,迄今为止算力最强的AI服务器。英伟达是如何实现这一点的呢?
答案很简单,就是靠暴力堆——开个玩笑,当然是他不惜重金研发的独门科技,和思路清晰的扩张方案。为了做到这一点,黄仁勋给出的答案是:将算力设计分成五个物理层次,并且在每一个层次都做到当前技术所允许的最好。黄仁勋说,Blackwell系列芯片的研发成本大概为100亿美金,这应该不是玩笑。
今天,我们就来对这5层算力做出层层解析。
第一层算力:单芯片算力
在同等工艺制程约束下,芯片的面积越大,晶体管的数量就越多。为了做出地球上最大的芯片,英伟达的Blackwell芯片尺是一整块wafer(晶圆)在光刻机曝光极限下所能支持的最大面积:800mm^2。按照CEO的原话说:如果我们做的再大一点,那么整块晶圆估计都会因为物理极限而断裂。
在很多人眼里,AI算力的本质就是流处理多核运算单元(Streaming Multiprocessor,SM,下同)的堆积。从某种意义上说,单一显卡的算力确实是可以这么计算,通过增加SM提升算力,这也是为什么华为的晟腾处理器910B号称在某些程度上已经接近A100的水平了。
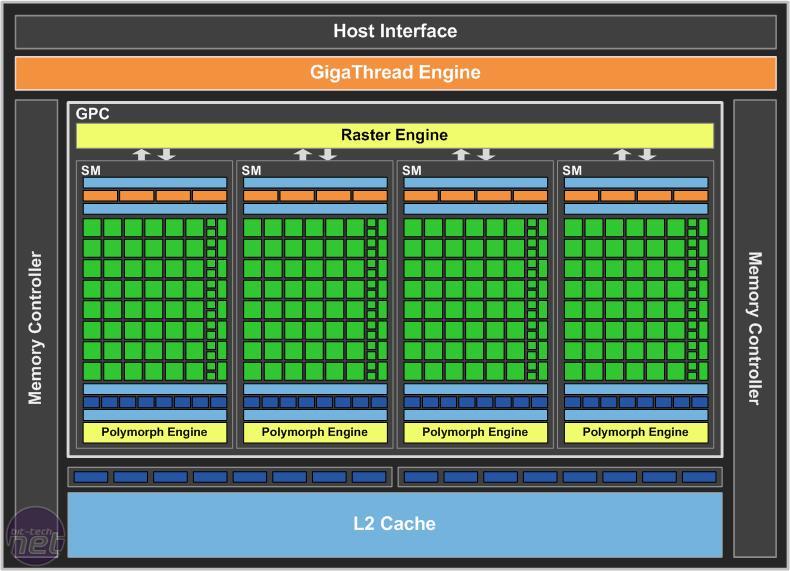
虽然接下来我们将会看到,单显卡算力只是AI算力的第一级层次,但这并不妨碍我们探寻一下2024年全新发布的Blackwell,在单卡算力方面究竟取得了什么进展?
为了回答这个问题,我们先回顾一下历代英伟达AI加速卡的算力发展史:
英伟达的第一代AI加速卡叫Volta ,是英伟达第一次为AI运算专门设计的张量运算(Tensor Core)架构。该架构GPU V100 包含80个SM单元,每个单元内有4个双核Block共计8个计算核心(下同),每个核心一个周期可以完成128个16位浮点数乘法累加。V100的运行频率是1.53GHz,稍微计算一下可知,V100的浮点计算算力为80*8*128*1.53GHz = 125 Tera FLOPS,简写成125 TFLOPS。

为方便大家理解,这里对名词缩写稍微进行一些解释:FLOPS是 FLoating point Operations Per Second的缩写,也即每秒浮点运算数。Tera是一种科学计数法的单位,1 Tera 等于 1000 Giga。这里的Tera和我们硬盘中的1TB中的T代表的是一个数量级。
英伟达的第二代张量计算架构叫图灵(Turing),代表显卡T4。一张T4显卡中只有40个SM,其他数据和V100基本接近,因此T4的算力基本只有V100的一半,也即65 TFLOPS。
至于为什么图灵架构的单卡Tensor算力不升反降,可能因为他其实是为游戏卡而生所致。
第三代张量运算架构安培(Ampere),终于来到我们比较熟悉的A100系列显卡了。在芯片工艺升级的加持下,单卡SM翻倍到了108个,SM内的核心数和V100相同,但是通过计算单元电路升级,核心每一个周期可以完成256个浮点数乘累加,是老架构的两倍。主频稍微下降,并且加入了更符合当时深度学习需要的8位浮点(FP8)运算模式,一个16位浮点核心可以当作2个8位浮点核心计算,算力再翻倍。主频稍有下降,为1.41GHz。因此最后,A100显卡的算力达到了V100的近5倍,为108*8*256*1.41GHz*2 =624 TFLOPS (FP8)。

第四代架构Hopper,也就是英伟达去年刚发布、OpenAI大语言模型训练已经采用、且因算力问题被禁运的H100系列显卡。该显卡的SM数(132个)相较前代并未大幅提升,但是因为全新的Tensor Core架构和异步内存设计,单个SM核心一个周期可以完成的FP16乘累加数再翻一倍,达到512次。主频稍微提高到1.83GHz,最终单卡算力达成惊人的1978 Tera FLOPS(FP8),也即首次来到了PFLOPS(1.97 Peta FLOPS)领域。同样地,1 PFLOPS = 1000 TFLOPS。大家家里的硬盘如果再扩容一千倍,就有1PB了。这一般是大型数据中心的储存单位。

老黄上周发布的第五代架构Blackwell,在这个算力天梯上又取得了什么样的进展呢?根据公开的数据,如果采用全新的FP4数据单元,GB200在将能在推理任务中达到20 Peta FLOPS算力。将其还原回FP8,应该也有惊人的10 PFLOPS,这相对H100提升将达到5倍左右。
公开数据显示,Blackwell的处理器主频为2.1GHz。假设架构没有大幅更新,这意味着Blackwell将有600个SM,是H100的接近4倍。Blackwell有两个Die,那么单Die显卡的SM数也达到了H100的2倍。
由此可见,晶圆面积和芯片大小,对Blackwell的算力至少做出了一半的贡献。这种提升是光刻工艺、芯片蚀刻、晶圆物理限制方面的提升,也就是我们所说的,第一个层次的提升。
当然,这些年英伟达在Tensor Core架构设计上的不断精进,包括为Transformer优化过的流水线和专属CUDA驱动,也为算力的提升做出了重要贡献:

这里,我们将从Volta架构至今的算力天梯进展图列表如下,方便大家查阅:
| 架构 | SM数 | 每周期乘累加 | 主频(Hz) | 算力(FP8) | 算力(FP16) |
| Volta | 80 | 128 | 1.53G | N/A | 125 TFLOPS |
| Turing | 40 | 128 | 1.59G | N/A | 65 TFLOPS |
| Ampere | 108 | 256 | 1.41G | 624 TFLOPS | 312 TFLOPS |
| Hopper | 132 | 512 | 1.83G | 1.97 PFLOPS | 985 TFLOPS |
| Blackwell | 600 | 512 | 2.1G | 10 PFLOPS | 5 PFLOPS |
由上表可知,Blackwell算力提升,主要来自于SM数的增加。总算力相较2023年推出的Hopper,提升约为5倍。相比2017年推出的Volta架构,提升约为40倍。
第二层算力:Die-to-Die相通,一片双芯
Blackwell能够做到600个SM的根本原因,在于他做出了世界上最大的Chiplet:把两个GPU核心直接“粘”起来,变成一个大小突破单一晶圆物理限制,通信速度达到10TB/s以至于两个核心会认为自己是一块芯片的巨无霸。
注意:对于今天的特别内容,只需输入您的邮箱,免费订阅即可阅读全文。全文约5800字


《“2024年3月23日特别篇:英伟达算力的五个层次,24年GTC大会GB200技术全拆解”》 有 4 条评论